Edge AI Hardware Guide 2026: Jetson vs Mac Mini vs NUC — Real Specs, Real Costs
Edge AI Hardware Guide 2026: Jetson vs Mac Mini vs NUC
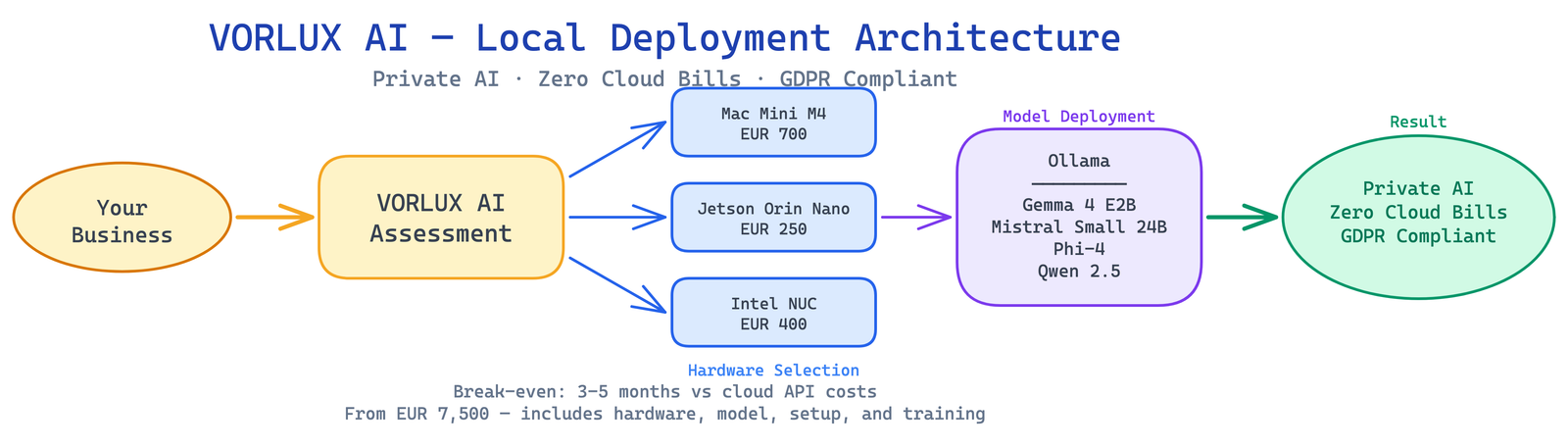
Choosing hardware for local AI deployment shouldn’t require a PhD in GPU architecture. After deploying models on all three major platforms for our clients, here’s our straightforward comparison — with the real specs, not marketing fluff.
The Three Contenders
NVIDIA Jetson Orin Nano Super — EUR 250
The Jetson Orin Nano Super is NVIDIA’s edge AI platform, designed specifically for AI inference at low power. It’s not a general-purpose computer — it’s a purpose-built AI accelerator.
Real specs (from NVIDIA’s official page):
- AI Performance: 67 TOPS (with the Super software update — up from 40 TOPS)
- GPU: 1024-core NVIDIA Ampere architecture with 32 Tensor Cores
- CPU: 6-core Arm Cortex-A78AE
- Memory: 8GB 128-bit LPDDR5 (102 GB/s bandwidth)
- Storage: microSD slot + M.2 NVMe SSD support
- Power: 7-15W configurable TDP
- OS: JetPack (Ubuntu-based Linux)
What it can run: Gemma 2 2B, Phi-3 Mini, small quantized models. Ideal for vision AI, object detection, and lightweight NLP. Cannot run 7B+ models at usable speed.
Apple Mac Mini M4 — EUR 700
The Mac Mini M4 (late 2024) is Apple’s most compact desktop, with unified memory that’s shared between CPU and GPU — perfect for AI inference because the model doesn’t need to be copied to a separate GPU.
Real specs (from Apple’s official specs):
- CPU: 10-core Apple M4 (4 performance + 6 efficiency cores)
- GPU: 10-core Apple GPU
- Neural Engine: 16-core (38 TOPS)
- Memory: 16GB unified memory (base), configurable to 24GB or 32GB
- Memory bandwidth: 120 GB/s
- Storage: 256GB SSD (base), up to 2TB
- Power: ~15W idle, ~45W under load
- OS: macOS (supports Ollama, llama.cpp, MLX natively)
M4 Pro upgrade (EUR 1,400+): 12-core CPU, 16-core GPU, up to 48GB or 64GB unified memory, 273 GB/s bandwidth. This is what we recommend for running 7B-14B models in production.
What it can run: With 16GB: Gemma 2 9B (Q4), Phi-4 (Q4), Mistral 7B. With 32GB+ (M4 Pro): Mistral Small 24B, Qwen 2.5 14B, Llama 3 8B (all quantized). With 48-64GB (M4 Pro): Llama 3.3 70B (Q4).
Intel NUC (Mini PC) — EUR 300-600
The Intel NUC is a general-purpose mini PC. For AI, you’ll want one with an Intel Core Ultra processor (which has a built-in NPU) or add an eGPU via Thunderbolt.
Typical specs (varies by model):
- CPU: Intel Core Ultra 7 155H (or similar)
- NPU: Intel AI Boost (11-34 TOPS depending on model)
- GPU: Intel Arc integrated (or eGPU via Thunderbolt 4)
- Memory: 16-64GB DDR5 (configurable)
- Storage: M.2 NVMe SSD
- Power: 28-65W TDP
- OS: Windows 11 or Linux
What it can run: With integrated GPU only: limited to small models (2-3B). With eGPU (RTX 4060/4070): similar to Mac Mini M4. Better as a general-purpose server that happens to run AI, rather than a dedicated AI device.
Head-to-Head Comparison
| Spec | Jetson Orin Nano Super | Mac Mini M4 (base) | Mac Mini M4 Pro | Intel NUC Ultra |
|---|---|---|---|---|
| Price | EUR 250 | EUR 700 | EUR 1,400+ | EUR 300-600 |
| AI TOPS | 67 | 38 | 38+ | 11-34 |
| Usable VRAM for LLMs | 8GB shared | 16GB unified | 48-64GB unified | 16-64GB DDR5 (CPU only) |
| Largest model (Q4) | 2-3B | 9B | 70B | 3-7B (no eGPU) |
| Power draw | 7-15W | 15-45W | 25-65W | 28-65W |
| Noise | Fanless option | Near-silent | Quiet | Varies |
| OS | Linux (JetPack) | macOS | macOS | Windows/Linux |
| Ollama support | Partial (ARM) | Native | Native | Via CPU or eGPU |
flowchart TD
BUDGET{"Budget?"}
BUDGET -->|"< EUR 300"| JETSON["Jetson Orin Nano<br/>8GB, EUR 250"]
BUDGET -->|"EUR 500-900"| MINI["Mac Mini M4<br/>16-24GB, EUR 700"]
BUDGET -->|"EUR 1000+"| STUDIO["Mac Studio<br/>48-96GB, EUR 2200+"]
JETSON --> USE1["QA bots, classification"]
MINI --> USE2["Full office assistant"]
STUDIO --> USE3["Enterprise multi-model"]Our Recommendations
For computer vision and IoT: Jetson Orin Nano (EUR 250)
If your use case is camera-based (warehouse monitoring, quality inspection, security) rather than text-based, the Jetson’s 67 TOPS and NVIDIA ecosystem (DeepStream, TensorRT) are unbeatable at this price.
For local LLM deployment: Mac Mini M4 Pro (EUR 1,400)
This is our top recommendation for European SMEs. The 48GB unified memory runs Mistral Small 24B or even Llama 3.3 70B (quantized). macOS + Ollama is the smoothest deployment path. Silent operation, tiny footprint, plugs into a monitor if you need a GUI.
For budget LLM deployment: Mac Mini M4 base (EUR 700)
The 16GB base model runs Gemma 2 9B and Phi-4 — enough for document summarization, customer support, and basic RAG. Best value for companies testing local AI before committing to larger models.
For general-purpose server + AI: Intel NUC (EUR 400)
Choose this if you need Windows compatibility, plan to add an eGPU later, or need the device to double as a file server / development machine. Not our first choice for pure AI inference.
Total Cost of Ownership (12 Months)
| Jetson | Mac Mini M4 | Mac Mini M4 Pro | Cloud API (equivalent) | |
|---|---|---|---|---|
| Hardware | EUR 250 | EUR 700 | EUR 1,400 | EUR 0 |
| Electricity (12mo) | EUR 15 | EUR 50 | EUR 70 | EUR 0 |
| API costs (12mo) | EUR 0 | EUR 0 | EUR 0 | EUR 2,400-12,000 |
| Total Year 1 | EUR 265 | EUR 750 | EUR 1,470 | EUR 2,400-12,000 |
The break-even point for a Mac Mini M4 Pro vs cloud APIs is typically 2-4 months. For a detailed cost breakdown, see our cloud vs local AI cost analysis.
Getting Started
Whichever hardware you choose, the deployment path starts with Ollama:
# On Mac Mini (macOS)
brew install ollama
ollama pull gemma2:9b # 16GB Mac Mini
ollama pull mistral-small # 32GB+ Mac Mini
# On Jetson (Linux)
curl -fsSL https://ollama.com/install.sh | sh
ollama pull gemma2:2b # Fits in 8GB
# On Intel NUC (Linux/Windows)
# Install Ollama from ollama.com, then:
ollama pull phi4 # 14B model, ~8GB Q4What We Deploy for Clients
At VORLUX AI, our standard client deployment is a Mac Mini M4 Pro with 48GB running Ollama. It handles:
- Mistral Small 24B for multilingual customer support
- Gemma 2 9B for document processing
- Phi-4 for mathematical and analytical tasks
The total cost including setup, model tuning, and our deployment service starts at EUR 7,500 — less than 4 months of equivalent cloud API spending.
Want help choosing the right hardware for your business? We assess your specific workload, recommend the right device, and handle the full deployment. Book a free 15-minute assessment →
Related: Best Local LLM Models Q2 2026 | Cloud vs Local AI Costs | Kit Digital Grants
Sources: NVIDIA Jetson Orin Nano Super · Apple Mac Mini M4 Specs · Ollama
Related reading
- Fine-Tune AI Models on Your Own Hardware: The LoRA Guide for SMEs
- NPU vs GPU: Why Neural Processing Units Are the Future of Edge AI
- Quantization Explained: How to Run 70B AI Models on a €700 Mac Mini
Ready to Get Started?
VORLUX AI helps Spanish and European businesses deploy AI solutions that stay on your hardware, under your control. Whether you need edge AI deployment, LMS integration, or EU AI Act compliance consulting — we can help.
Book a free discovery call to discuss your AI strategy, or explore our services to see how we work.